Redis实战中遇到的一些问题
Redis分布式锁
无论使用哪种技术组件,做分布式锁都要满足四个基本要求:
互斥性:同一个时刻,只能又一个客户端获取到锁,在它解锁之前,其他客户端无法加锁;
不能死锁:加锁和解锁这两个动作必须成对出现,加锁后必须解锁,否则其他客户端就无法再加锁;
“解铃还须系铃人”:同一把锁,其加锁和解锁两个动作必须由同一个客户端完成,即一个客户端不能释放另一个客户端加的锁;
容错性:不能出现单点故障,锁的实现者或提供者必须保证客户端可以稳定的获取到锁;
Redis如何满足上述四个要求呢?
互斥性可以使用SETNX命令来保证,这个命令只有在key不存在时才会生效,若key已经存在那么就是返回失败,key充当了锁的角色;
不能死锁这个特性可以由EXPIRE命令实现,它可以给某个key设置生存时间,过期后自动删除,这是一种兜底机制,防止某个客户端加锁后死机没能解锁,可以由redis自己来解锁;
“解铃还须系铃人“这个特性是通过比较key对应的value来实现的,每个客户端在加锁时,为对应的key设置一个全局唯一的value(即这个value其他客户端无法获取到),解锁时先获取key当前的value,和自己的value比对,一致时才能进行后续的解锁步骤,否则返回失败;
容错性这个特性,更多的需要redis集群来实现,单机无法保证这一点。
以上是理论部分,具体到实践中,仍有一下几个需要注意的地方:
客户端向redis server发送SETNX命令后可能会死机,没有发送EXPIRE命令,这会导致死锁,所以必须将两个命令原子化,客户端只需向redis server发送一次请求,有两个办法可以做到这一点:一是使用lua脚本;二是使用2.6.12 版本之后的带有多个参数的set命令,可以同时达到setnx和expire命令的效果。第二种方法在GO语言的go-redis框架中,实现如下:
1
redisClient.SetNX(key, value, expiration)
解锁时,理论上需要两个步骤:先判断当前key对应的value和自己一致,再删除key,即先发送get再发送delete请求;实际执行时也需要将两步操作原子化,否则get请求后锁马上过期了,然后被另一个客户端上锁,这时如果value一致要执行delete操作,就违背第三个特性了。redis目前还没有将get和delete柔和在一起的命令,只能通过lua脚本实现,如下:
1
2
3luaScript = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end"
redisClient.Eval(luaScript, []string{key}, value)lua脚本在redis执行的时候是原子化的,整个脚本中的命令要么全部执行成功,要么一起失败。
关于容错性,必须借助redis集群来实现,但是集群模式下,节点之间存在数据一致性问题,这时必须引入redlock算法,这个算法的java版实现叫Redisson,感兴趣可以自行搜索,本篇不再过多介绍。//TODO
缓存更新的套路
缓存中的数据只是数据源的一个镜像,用来减轻数据源的读请求压力。那么当数据发生变化时,要如何协调缓存和数据源的更新操作?我们来模拟一下:
- 先删除缓存,再更新数据库。
线程一:删除缓存———————————————更新数据库
线程二: 读缓存 – 空 – 读数据源 – 更新缓存
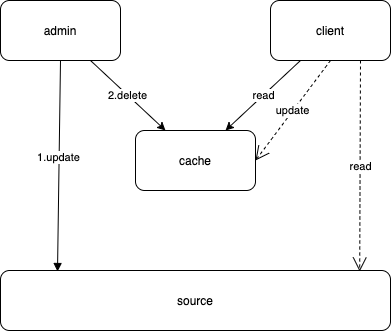
并发场景下,线程一删除缓存后,线程二重新载入了缓存,此时线程一还没来得及更新数据源,所以缓存中是过时的脏数据。
- 先更新数据库,再删除缓存。
线程一: 更新数据库 – 删除缓存
线程二:读缓存 – 空 – 读数据源 ——————————更新缓存
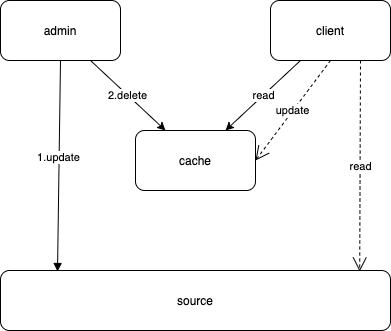
好像出现了同样的问题,但是概率降低了很多:首先是读线程访问缓存的时候,数据恰好失效了;同时它在读数据源的时候,恰好遭遇了写线程,而且先读再写;另外,在操作缓存的时候,还必须是写线程先删除了缓存(虽然此时缓存已经失效),读线程再更新缓存。这几件事叠加在一起同时发生的概率几乎可以忽略不计。所以总体来说,这个方案是安全的,Facebook也是采用的这种方案。
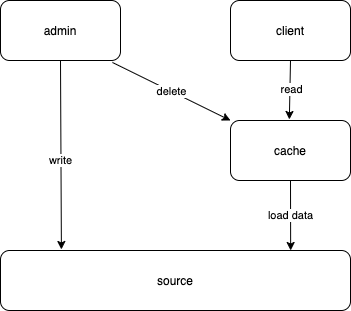
- Read Through
这种模式下,读请求不允许访问数据源,只能访问缓存。没命中的情况下,等待缓存自己去加载数据源,更新缓存后返回;而写请求用来更新数据源,然后删除缓存。如下图:
- Write Through
读请求仍然止步于缓存层,写请求直接去更新缓存:如果写请求没有命中缓存,则直接更新数据库;如果命中缓存,直接更新缓存,然后缓存自己去更新数据库(这两个动作是原子的)。
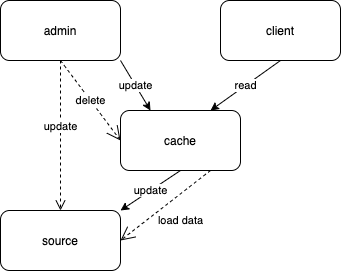
- Write Back
基本思路同上,但是写请求更新缓存和缓存自己更新数据库不再是同步的,“更新数据”这个动作变成了缓存去异步批量处理。这样做的好处是,数据库的IO效率会特别高,但是缺点是可能会有失败情况,这时数据源和缓存的数据不再是强一致性。也算是一种Trade-Off吧。
缓存穿透
缓存穿透指的是:key在数据源并不存在,每次针对此key的请求从缓存获取不到,请求都会到数据源,但是数据源也没有,那么频繁访问这个key可能会压垮数据源。
解决方案:
(1)枚举法:将所有可能的key枚举出来,存储到某个容器中,缓存没有命中的时候先在容器中筛选,容器中若没有这个key,直接打回,不必访问数据源。这种思路的缺点是需要额外维护这个容器,比如更新key,业界常用的实现是布隆过滤器。
(2)null法:数据源中也不存在的key,可以在缓存中加上这个key,并将其值赋为null,同时设置几分钟的过期时间,防止后面数据真的出现这个key了。它的缺点也很明显,因为黑客共计不可能只使用一个key,这样到时缓存将出现大量值为null的key,浪费存储并使redis效率降低。
需结合具体业务场景,灵活选择合适的思路。如果key是固定的,枚举法显然更合适;但是key处于不停的变化之中,枚举法就不那么合适了。
缓存击穿
缓存击穿与缓存穿透的区别在于,此时key在数据源中是真实存在的。但是如果key失效的同时仍有大量的并发访问,这些访问最终都会落到数据源上,仍有可能压垮数据源。
解决方案:
缓存中的key失效,最终还是要重新从数据源获取的,现在的问题在于有太多请求了,不能都让它们访问数据源,其实只要一个访问就行了,其他请求先阻塞;等这个请求访问数据源成功后可以刷新缓存,这时key又存在了,这时其他请求就可以直接从缓存获取而不必访问数据源了。示例代码如下:
1 | func Get(key) string { |
缓存雪崩
与缓存击穿的区别在于,雪崩时是多个key同时失效,这些key未必是热点key,也就是虽然每个key的访问量不高,但是很多key累加起来,也会对数据源造成冲击,甚至拖垮。
对于热点key我们可以采用上述办法解决,但是对于非热点key就不起作用了,而且也无法提前判断哪些key将会成为热点。
最好的办法就是尽可能的分散key过期的时间,对设置key的失效时间保持敏感,必须提前考虑到集体失效的极端情况。可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。